A major challenge for a data analyst is working within an organization with people who do not have an analytical background. The reason this is difficult is that the data analyst has to try and determine what the audience of his analysis wants him to analyze. This is further complicated when the consumers of the results are not able to fully articulate what they want to know and lean on their intuition and understanding of the context. The analyst who lacks this shared experience is left to figure out what to do.

The wording and language used by non-data and data people to develop questions are similar but different. To be fair, it is not the responsibility of the non-analyst to understand how to form analytical questions. However, it is the data analyst’s responsibility to speak the language of the non-data people and to translate the business questions that are provided into analytical questions.
In this post, we will look at business and analytical questions and how they are shaped and formed.
Definitions
Business questions are questions developed by non-technical individuals within an organization. These questions are derived from the business goals of the organization. The goals of the business or organization are often targets that need to be met over a period of time. An example of an organizational goal would be
To reduce turnover by 10% over a year
The business question that could be extracted from this goal could be
What programs should we use to reduce turnover?
The question above is a business or organizational question. However, this is not a question that a data analyst could answer in its current format. Whereas business questions are broad and open-ended analytical questions are specific. At times, it may be necessary to develop several analytical questions to answer one business question due to the need for specificity. One way to reword the business question above for data analysis is shown below.
Which if any of the turnover reduction programs implemented over the past year were able to reduce turnover by at least 10% in the sample population?
There are several assumptions in this question that were not built into the original business question
- There are several turnover reduction programs
- The sample population was broken into various groups and each group experienced one type of turnover reduction program
- Each program was given one year in length and was run concurrently
- There was a way to collect data in a scientific manner
- People were appropriately trained to implement the various turnover reduction programs
- etc.
As you can see this can truly get complicated. The data analyst may not only focus on the analysis but may be called upon to shape how data will also be collected and or the research design. As mentioned in the introduction, business experts often know what they want but are not able to articulate it clearly and they struggle with developing the linear process that is needed to collect and analyze the data.
Often, the data analyst’s challenge may be a lack of experience in the field in which they have to analyze data. For example, an individual with a background in education may have to analyze health data. The analytical techniques are the same in terms of the data but a lack of knowledge in the context of health care can make it difficult to get things done. The real problem is that the business people know the context but not the data analysis while the data analysis knows the numbers but not the context.
Conclusion
The primary difference between a business and an analytical question is the amount of detail. A business question is a broad overview that may not articulate all that is needed to develop an answer. An analytical question is detail-oriented and captures all that is needed in terms of obtaining an answer using whatever statistical techniques are needed. Business experts have contextual knowledge but may not have analytical knowledge while the data analyst is burdened to have both contextual knowledge and analytical expertise to shape the questions so that they are answerable.
























































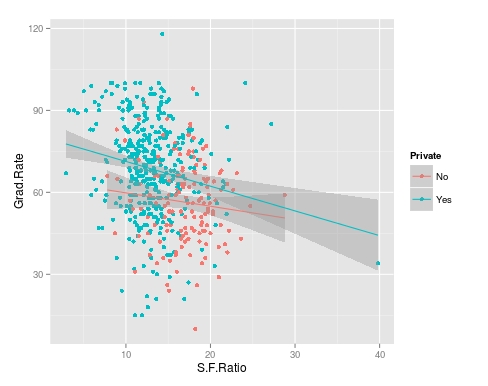
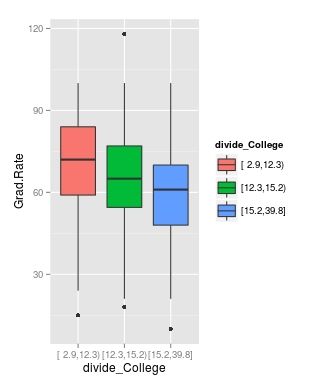



 Now we need to calculate the accuracy of the use of the word ‘money’ to predict spam. For our current example, we will simply use in “ifelse” function. If the frequency is greater than 0.1.
Now we need to calculate the accuracy of the use of the word ‘money’ to predict spam. For our current example, we will simply use in “ifelse” function. If the frequency is greater than 0.1.