In the last post about R, we looked at plotting information to make predictions. We will now look at an



We will use the same data as last time with the help of the ‘caret’ package as well. The code below sets up the seed and the training and testing set we need.
> library(caret); library(ISLR); library(ggplot2)
> data("College");set.seed(1)
> PracticeSet<-createDataPartition(y=College$Grad.Rate, + p=0.5, list=FALSE) > TrainingSet<-College[PracticeSet, ]; TestingSet<- + College[-PracticeSet, ] > head(TrainingSet)
The code above should look familiar from the previous post.
Make the Scatterplot
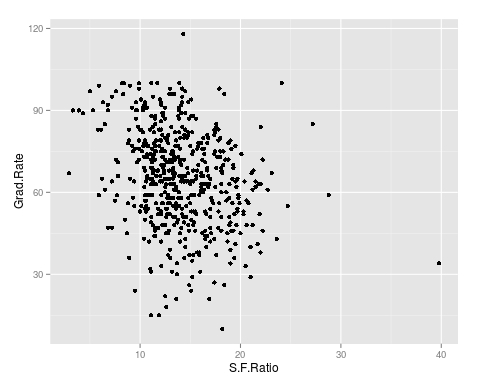
We will now create the scatterplot showing the relationship between “S.F. Ratio” and “Grad.Rate” with the code below and the scatterplot.
> plot(TrainingSet$S.F.Ratio, TrainingSet$Grad.Rate, pch=5, col="green", xlab="Student Faculty Ratio", ylab="Graduation Rate")


Here is what we did
- We used the ‘plot’ function to make this scatterplot. The x variable was ‘S.F.Ratio’ of the ‘TrainingSet’ the y variable was ‘Grad.Rate’.
- We picked the type of dot to use using the ‘pch’ argument and choosing ’19’
- Next, we chose a color and labeled each axis
Fitting the Model
We will now develop the linear model. This model will help us to predict future models. Furthermore, we will compare the model of the Training Set with the Test Set. Below is the code for developing the model.
> TrainingModel<-lm(Grad.Rate~S.F.Ratio, data=TrainingSet) > summary(TrainingModel)
How to interpret this information was presented in a previous post. However, to summarize, we can say that when the student to faculty ratio increases one the graduation rate decreases 1.29. In other words, an increase in the student to faculty ratio leads to decrease in the graduation rate.
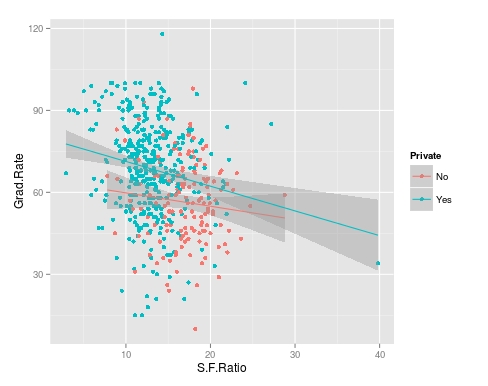
Adding the Regression Line to the Plot
Below is the code for adding the regression line followed by the scatterplot
> plot(TrainingSet$S.F.Ratio, TrainingSet$Grad.Rate, pch=19, col="green", xlab="Student Faculty Ratio", ylab="Graduation Rate") > lines(TrainingSet$S.F.Ratio, TrainingModel$fitted, lwd=3)


Predicting New Values
With our model complete we can now predict values. For our example, we will only predict one value. We want to know what the graduation rate would be if we have a student to faculty ratio of 33. Below is the code for this with the answer
> newdata<-data.frame(S.F.Ratio=33) > predict(TrainingModel, newdata) 1 40.6811
Here is what we did
- We made a variable called ‘newdata’ and stored a data frame in it with a variable called ‘S.F.Ratio’ with a value of 33. This is x value
- Next, we used the ‘predict’ function from the ‘caret’ package to determine what the graduation rate would be if the student to faculty ratio is 33. To do this we told caret to use the ‘TrainingModel’ we developed using regression and to run this model with the information in the ‘newdata’ dataframe
- The answer was 40.68. This means that if the student to faculty ratio is 33 at a university then the graduation rate would be about 41%.
Testing the Model
We will now test the model we made with the training set with the testing set. First, we will make a visual of both models by using the “plot” function. Below is the code follow by the plots.
par(mfrow=c(1,2))
plot(TrainingSet$S.F.Ratio,
TrainingSet$Grad.Rate, pch=19, col=’green’, xlab=”Student Faculty Ratio”, ylab=’Graduation Rate’)
lines(TrainingSet$S.F.Ratio, predict(TrainingModel), lwd=3)
plot(TestingSet$S.F.Ratio, TestingSet$Grad.Rate, pch=19, col=’purple’,
xlab=”Student Faculty Ratio”, ylab=’Graduation Rate’)
lines(TestingSet$S.F.Ratio, predict(TrainingModel, newdata = TestingSet),lwd=3)


In the code, all that is new is the “par” function which allows us to see to plots at the same time. We also used the ‘predict’ function to set the plots. As you can see, the two plots are somewhat differ based on a visual inspection. To determine how much so, we need to calculate the error. This is done through computing the root mean square error as shown below.
> sqrt(sum((TrainingModel$fitted-TrainingSet$Grad.Rate)^2)) [1] 328.9992 > sqrt(sum((predict(TrainingModel, newdata=TestingSet)-TestingSet$Grad.Rate)^2)) [1] 315.0409
The main take away from this complicated calculation is the number 328.9992 and 315.0409. These numbers tell you the amount of error in the training model and testing model. The lower the number the better the model. Since the error number in the testing set is lower than the training set we know that our model actually improves when using the testing set. This means that our model is beneficial in assessing graduation rates. If there were problems we may consider using other variables in the model.
Conclusion
This post shared ways to develop a regression model for the purpose of prediction and for model testing.