

In this post we are going to learn how to do web scrapping with R.Web scraping is a process for extracting data from a website. We have all done web scraping before. For example, whenever you copy and paste something from a website into another document such as Word this is an example of web scraping. Technically, this is an example of manual web scraping. The main problem with manual web scraping is that it is labor intensive and takes a great deal of time.
Another problem with web scraping is that the data can come in an unstructured manner. This means that you have to organize it in some way in order to conduct a meaningful analysis. This also means that you must have a clear purpose for what you are scraping along with answerable questions. Otherwise, it is easy to become confused quickly when web scraping

Therefore, we will learn how to automate this process using R. We will need the help of the “rest” and “xml2” packages to do this. Below is some initial code
library(rvest);library(xml2)For our example, we are going to scrape the titles and prices of books from a webpage on Amazon. When simply want to make an organized data frame. The first thing we need to do is load the URL into R and have R read the website using the “read_html” function. The code is below.
url<-'https://www.amazon.com/s/ref=nb_sb_noss?url=search-alias%3Daps&field-keywords=books'
webpage<-read_html(url)We now need to specifically harvest the titles from the webpage as this is one of our goals. There are at least two ways to do this. If you are an expert in HTML you can find the information by inspecting the page’s HTML. Another way is to the selectorGadget extension available in Chrome. When using this extension you simply click on the information you want to inspect and it gives you the CSS selector for that particular element. This is shown below
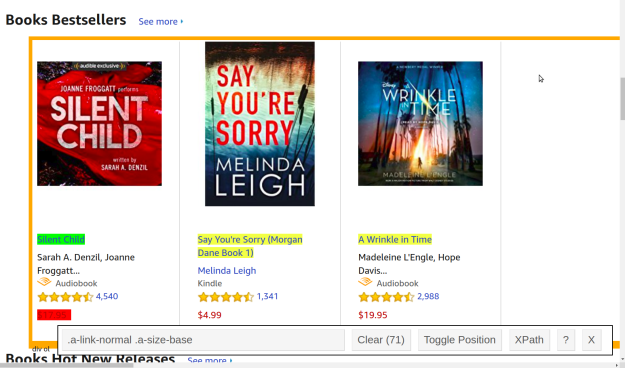
The green highlight is the CSS selector that you clicked on. The yellow represents all other elements that have the same CSS selector. The red represents what you do not want to be included. In this picture, I do not want the price because I want to scrape this separately.
Once you find your information you want to copy the CSS element information in the bar at the bottom of the picture. This information is then pasted into R and use the “html_nodes” function to pull this specific information from the webpage.
bookTitle<- html_nodes(webpage,'.a-link-normal .a-size-base')We now need to convert this information to text and we are done.
title <- html_text(bookTitle, trim = TRUE) Next, we repeat this process for the price.
bookPrice<- html_nodes(webpage,'.acs_product-price__buying')
price <- html_text(bookPrice, trim = TRUE) Lastly, we make our data frame with all of our information.
books<-as.data.frame(title)
books$price<-priceWith this done we can do basic statistical analysis such as the mean, standard deviation, histogram, etc. This was not a complex example but the basics of pulling data was provided. Below is what the first few entries of the data frame look like.
head(books)
## title price
## 1 Silent Child $17.95
## 2 Say You're Sorry (Morgan Dane Book 1) $4.99
## 3 A Wrinkle in Time $19.95
## 4 The Whiskey Sea $3.99
## 5 Speaking in Bones: A Novel $2.99
## 6 Harry Potter and the Sorcerer's Stone $8.99Conclusion
Web scraping using automated tools saves time and increases the possibilities of data analysis. The most important thing to remember is to understand what exactly it is you want to know. Otherwise, you will quickly become lost due to the overwhelming amounts of available information.
very good knowledgeable content. this really helps with Scraper API our website
i really appreciate it. thanks for sharing your knowledge